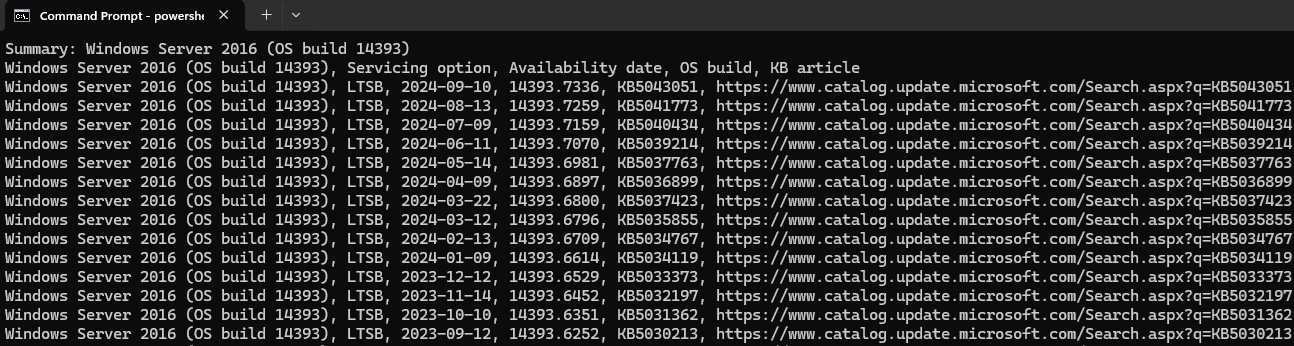
I hacked together a small tool in .NET that helps me quickly analyze the Component Based Servicing (CBS) log in c:\windows\logs\cbs\cbs.log for missing CSI Payloads.
It will parse the log file selected and extract the packages. A few options are available to then search for the missing payloads by specifying a source directory (like a known good copy of \windows\winsxs folder.
This GUI is a culmination of a few PowerShell scripts I hacked together to basically do the same thing. The only thing I do not have in the GUI is the ability to convert the UBR to a KB, so for example if a missing package for Windows Server 2019 is amd64_microsoft-windows-f..rcluster-clientcore_31bf3856ad364e35_10.0.17763.3469_none_decef48d0a3310cc, the UBR is 3469 and that is found in KB5017379 which can be determined by visiting Microsoft’s Windows Server release information.
I did write a PowerShell script that retrieves the Windows Server release information, if anyone is interested. It takes an argument (win10, win11, server2019, server2022) and defaults to server2019 if no argument provided.
The PowerShell version of this is available in my GitHub repo.
Check CBS Corruption
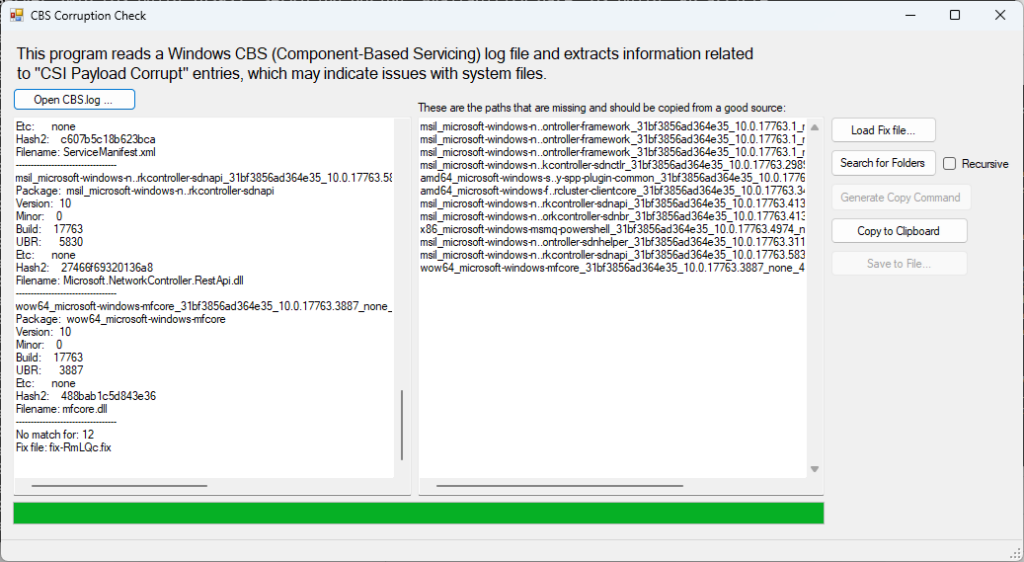
This is the main interface. After selecting the CBS log file, it will parse it and display any lines with CSI Payload Missing. It writes a .fix file and displays the contents on the right pane. These are the missing folders.
From there, a few options I needed was to copy to clipboard, and also generate copy command. The generate copy command just utilizes robocopy and hardcodes a fake destination that will need changed. Alternatively, you can use the Search for Folders button and choose a source folder to search. By default it will start in c:\windows\winsxs. If you want to use recursion, be sure to check the recursive checkbox.
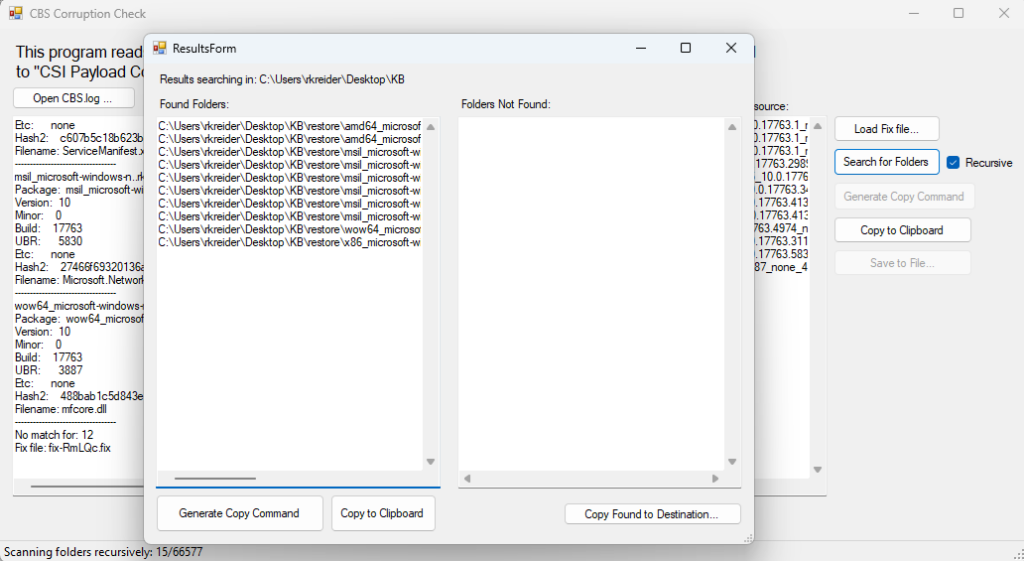
This is the results of the Search for Folders button. If it finds files, the left pane lists the location where the folders are. You can then use the Copy Found to destination button which lets you choose a destination folder and will then copy the found folders entirely to the destination. Alternatively a couple options exist to Copy to Clipboard and Generate Copy Command (which generates a robocopy command like previous).